
티스토리 뷰
0503. One-Hot-Encoding(Scikit-learn) / train 평가 / cross validation 기법
니츄 2023. 3. 14. 13:11
※ Extra 모델을 불러온 후, cross_val_predict로 예측 및 평가하고, cross validation 기법을 사용하여 모델을 평가.
📝 train_test_split()
- arrays : 분할시킬 데이터
- test_size : 테스트 셋의 비율 (default = 0.25)
- train_size : 학습 데이터 셋의 비율
- random_state : 고정할 seed값
- shuffle : 기존 데이터를 나누기 전에 순서를 섞을 것인지 (default=True)
- stratify : 지정한 데이터의 비율을 유지. (= 층화표집)
📝 머신러닝 알고리즘의 데이터 : 문자 데이터를 사용할 수 없다.
| ★ 머신러닝 알고리즘의 종류 | 종류예시 | ||
| 지도학습 | 분류 (Classification) |
입력변수 X와 출력변수 Y가 주어졌을 때, 미지의 데이터가 어떤 클래스에 속하는지 예측하는 문제. |
- 로지스틱 회귀(Logistic Regression) - K-최근접 이웃(K-Nearest Neighbors) -서포트 벡터 머신 |
| 회귀 (Regression) |
입력변수 X와 출력변수 Y가 주어졌을 때, 미지의 데이터의 출력변수값을 예측하는 문제. |
- 선형회귀(Linear Regression) - 의사결정나무(Decision Tree) - 랜덤포레스트(Random Forest) - 그래디언트 부스팅 |
|
| 비지도학습 | 군집화 (Clustering) |
입력변수 X가 주어졌을 때, 서로 유사한 데이터들을 묶는 문제. |
- K-평균(K-Means) - DBSCAN(Density-Based Spatial Clustering of Applications with Noise) |
| 차원축소 (Dimensionality Reduction) |
고차원의 데이터를 저차원으로 축소하는 문제 | - 주성분 분석(PCA) - 특이값 분해 (SVD) |
|
| 강화학습 | - | 에이전트가 호나경과 상호작용하며, 행동(Action)을 통해 보상을 최대화하는 문제. |
- Q-러닝(Q-Learning) - 딥 강화학습 (Deep Reinforcement Learning) |
📝 sklearn.preprocessing.OneHotEncoder 매서드

sklearn.preprocessing.OneHotEncoder
Examples using sklearn.preprocessing.OneHotEncoder: Release Highlights for scikit-learn 1.1 Release Highlights for scikit-learn 1.1 Release Highlights for scikit-learn 1.0 Release Highlights for sc...
scikit-learn.org
📝binary encoding과 One hot encoding
- binary encoding을 하면 One hot encoding을 굳이할 필요가 없어진다.
- ※ binary 값을 찾는 방법
# 두 개의 값만 있는 컬럼만 추출해본다.
nuni = df.drop(columns=label_name).nunique()
bicols = nuni[nuni==2].index
bicols- One hot encoding을 할 때에는 필요한 'object' 데이터만 가져온다.
- 기존에 binary encoding을 했던 데이터 및 변수는 제외한다.
- 인코딩 결과는 'numpy array'형태로 나타난다.
df_train_ohe = pd.DataFrame(X_train_ohe.toarray(), columns=ohe.get_feature_names_out())- 인코딩한 값과 수치 데이터를 연결(concat) 하기 위해서는 같은 index를 사용하고 있어야 한다.
- 각각 변수에 넣어준 후 concat.
📝 엑스트라 트리모델이란?
: 더욱 랜덤한 포레스트로, 극도로 무작위화(Extremely Randomized)된 앙상블 러닝 모델.
- Extra Trees : 임의분할
- Random Forest : 최적분할
- 결정트리(DecisionTree)
- 데이터 샘플 수와 특성 설정까지 랜덤으로 지정한다.
Extra Trees 회귀
from sklearn.ensemble import ExtraTreesRegressor
# Building the model
extra_reg = ExtraTreesRegressor()
# Training the model
extra_reg.fit(X, y)더욱 랜덤한 포레스트-익스트림 랜덤 트리(ExtraTreesClassifier)
‘파이썬 라이브러리를을 활용한 머신러닝’ 2장의 지도학습에서 대표적인 앙상블 모델로 랜덤 포레스트를 소개하고 있습니다. 랜덤 포레스트는 부스트랩 샘플과 랜덤한 후보 특성들을 사용해
tensorflow.blog
📝머신러닝의 트리모델 종류 (출처 : chat gpt)
트리모델이란?
: 머신러닝에서 분류(Classificastion)와 회귀(Regression)문제를 해결하는 데에 많이 사용되는 모델.
입력 변수의 조건에 따라 데이터를 분할하며, 이를 통해 결과를 예측한다.
1. 결정트리(Decision Tree)
- 가장 기본적인 트리모델로, 입력 변수를 기준으로 데이터를 분할하는 모델입니다.
- 노드(Node)는 분할할 기준이 되는 입력 변수를 선택하며, 가지(Branch)는 각각의 선택지를 나타냅니다.
- 분류와 회귀 모두에 적용 가능합니다.
2. 랜덤 포레스트(Random Forest)
- 결정 트리를 여러 개 결합하여 만든 앙상블(Ensemble) 모델입니다.
- 각 트리마다 무작위로 선택한 일부 입력 변수를 사용하여 분할을 수행하므로, 일반적으로 과대적합(Overfitting) 문제를 줄일 수 있습니다.
- 분류와 회귀 모두에 적용 가능합니다.
3. 그래디언트 부스팅(Gradient Boosting)
- 여러 개의 결정 트리를 순차적으로 학습시켜 오류를 최소화하는 방향으로 모델을 개선해 나가는 앙상블 모델입니다.
- 이전 트리의 예측 결과와 실제 결과의 차이(잔차)를 새로운 입력 변수로 사용하여 다음 트리를 학습시킵니다.
- 회귀 문제에서 성능이 뛰어나며, 분류 문제에서도 사용 가능합니다.
4. XGBoost(eXtreme Gradient Boosting)
- 그래디언트 부스팅을 기반으로 하며, 더욱 빠르고 정확한 예측을 가능하게 한 모델입니다.
- 일부 데이터의 가중치를 높이거나 낮추는 기능과 과적합을 방지하기 위한 정규화(Regularization) 기능이 추가됩니다.
- 회귀와 분류 모두에 적용 가능합니다.
5. LightGBM(Light Gradient Boosting Machine)
- XGBoost와 마찬가지로 그래디언트 부스팅을 기반으로 하며, 빠른 학습 속도와 높은 정확도를 제공하는 모델입니다.
- 히스토그램 기반 근사치(Histogram-based Approximation) 알고리즘을 사용하여 빠르게 대용량 데이터셋을
★ 트리계열 알고리즘은 분할기법을 사용하기 때문에 스케일링 여부에 따라 성능의 차이가 크지 않다.
☆ 하지만 다른 알고리즘에서는 스케일링을 해야 성능이 잘 나오는 알고리즘도 있다.
📝 피처 중요도란?
# feature_importances_ 를 통해 모델의 피처 중요도를 추출합니다.
fi = pd.DataFrame(model.feature_importances_)
fi.index = model.feature_names_in_
fi = fi.sort_values(by=0)- 머신러닝 모델에서 각각의 피처(입력 변수)가 예측 결과에 영향을 미치는 정도를 나타내는 지표.
- 모델이 예측을 할 때 어떤 피처가 가장 영향력이 큰지를 평가하는 것.
- 결정트리 기반모델(Decision Tree) : 각 노드에서의 분할기준을 결정할 때 해당 피처의 중요도를 계산함.
- 랜덤 포레스트(Random Forest) : 앙상블(Ensemble) 모델에서는 각각의 트리에서 계산된 피처 중요도를
평균하여 전체 모델의 피처 중요도를 계산함.
- 피처 중요도를 계산하면, 모델의 예측 결과를 설명하거나 모델을 개선하는데 도움이 됨.
출처 : chat gpt
📝 Cross Validation : 교차검증

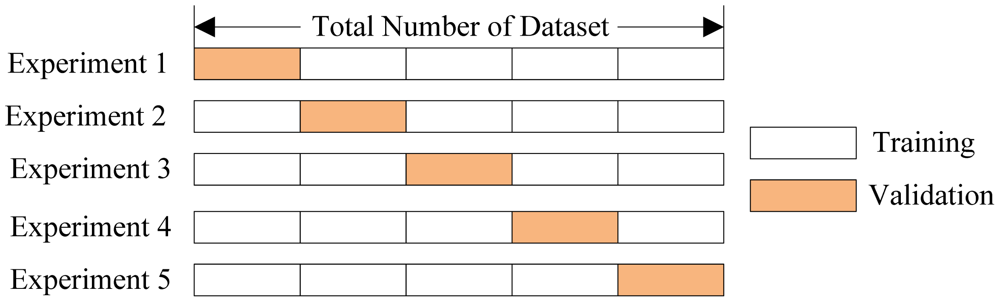
- Cross-validation : 신뢰가 중요한 경우. ex) 제품 출시 전 평가 등
- test가 아닌 train 데이터 셋을 사용한다.
- cross validation 은 실전 시험을 보기 전에 풀어보는 모의고사의 점수입니다.
test 는 실전 시험이기 때문에 모의고사에서 몇 점이 나왔는지를 보기위해 train 으로 점수를 평가합니다. - Hold-out-validation : 빠르게 모델을 평가하고자 할 때
sklearn.model_selection.cross_val_predict
Examples using sklearn.model_selection.cross_val_predict: Combine predictors using stacking Combine predictors using stacking Plotting Cross-Validated Predictions Plotting Cross-Validated Predictions
scikit-learn.org
📝 from sklearn.model_selection from (_____________)
- cross_val_predict : 예측 결과(추정치)만 반환, 점수를 직접 계산 => 다양한 측정 공식으로 점수 측정이 가능.
- cross_val_score : 교차검증을 통한 예측 점수를 반환
- cross_validate : 교차검증을 통해 지표를 평가하고 fit/score 시간도 기록.
- n_jobs : 사용할 코어 수 지정 가능. 그러나, cpu 코어수보다 크게 지정하는 것은 도움이 되지 않음.
'n_jobs = -1'로 지정하면 컴퓨터의 모든 코어를 사용함.
| # n_jobs : int, default=None # Number of jobs to run in parallel. Training the estimator and # predicting are parallelized over the cross-validation splits. # ``None`` means 1 unless in a :obj:`joblib.parallel_backend` context. # ``-1`` means using all processors. See :term:`Glossary <n_jobs>` # for more details. |
오늘의 복습 !
※ 머신러닝 알고리즘 알아보기
※ 트리 종류 개념 정리하고 비교하기
※ 피처중요도 알아보기
'TIL & WIL > Machine Learning' 카테고리의 다른 글
| XGBoost 알아보기 (0) | 2023.03.21 |
|---|---|
| 0601. ExtraTreesRegressor / CrossValidation / 회귀모델 평가 (0) | 2023.03.14 |
| 0502. 범주형 데이터/ One-Hot-Encoding(pd.get_dummies)/ RandomForest (0) | 2023.03.13 |
| 0501. Scikit-learn API기초 / DecisionTree (1) | 2023.03.13 |
| 머신러닝 분류 (2) (0) | 2023.03.09 |