Python 6일차. 판다스(Pandas) 실습해보기

* 아나콘다(Anaconda)
: JAVA, C, C++과 같이 Python이 아닌 다른 언어로 만들어진 것을 Python으로 구동하기 위해서는
해당 언어를 실행할 수 있는 환경이 필요하다. 아나콘다로 **접착제 언어의 특징을 갖는 라이브러리를
설치하게 되면, 이런 복잡한 환경에서 구동하는 도구들을 비교적 오류 없이 설치해 주게 된다.
**접착제 언어란?
: 다른 언어와의 호환성이 우수한 언어로, Numpy가 대표적인 접착제 언어의 특징을 갖는 라이브러리다.
* 판다스(Pandas)
* Pandas 실습하기
1) 필요한 라이브러리 로드하기
: pandas, numpy 불러오기
import pandas as pd
import numpy as np
# pandas의 축약어 : pd
# numpy 의 축약어 : np
2) 비어있는 데이터 프레임 생성하기

df = pd.DataFrame()
3) 컬럼 생성하기
: 영화제목이라는 컬럼에 영화제목 리스트 담기
**컬럼명에 특수문자, 띄어쓰기 등이 들어가면 쿼리를 쓰다 오류가 발생했을 때 찾기 어려워 권장하지 않음.
df["영화제목"] = ["어바웃타임", "mamma Mia!", "Minions", "유령신부", "피노키오", "soul", "Inside Out"]
df
4) 컬럼 추가하기
: 등급 컬럼을 만들어 '전체 관람가' 값 넣기.
df["등급"] = '전체 관람가'
df
5) 데이터의 타입 출력해보기
: '등급'과 df의 타입 각각 출력해보기
type(df["등급"])
type(df)
6) 등급을 리스트 값으로 변경하기
- 어바웃타임(15세 이상 / 8000원)
- mamma mia!(12세 이상 / 7000원)
- 그 외(전체 관람가 / 6000원)
va = ['15세 이상', '12세 이상', '전체 관람가', '전체 관람가', '전체 관람가', '전체 관람가', '전체 관람가']
df["등급"] = va
price = [8000, 7000, 6000, 6000, 6000, np.nan, 6000]
df["가격"] = price
df
**np.nan이란?
: not a number의 약자로 결측치를 의미한다. nan의 데이터 타입은 float이다.
df["가격"]
7) '개봉일', '평점' 컬럼 추가해보기
| 어바웃타임 | mamma mia! | Minions | 유령신부 | 피노키오 | soul | Inside Out | |
| 개봉일 | 2013 | 2008 | 2015 | 2005 | 2022 | 2021 | 2015 |
| 평 점 | 9.3 | 8.43 | 8.25 | 8.35 | 8.8 | 8.7 | 9.05 |
od = [2013, 2008, 2015, 2005, 2022, 2021, 2015]
df["개봉일"] = od
grade = [9.3, 8.43, 8.25, 8.35, 8.8, 8.7, 9.05]
df["평점"] = grade
df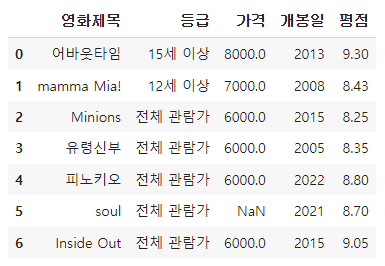
8) 실수로 컬럼을 잘못 추가했거나 삭제하고자 할 때
: 'df.drop(columns, axis = n)' 코드를 사용하기
# axis=0 : 행(row)
# axis=1 : 열(column)
df = df.drop("가격", axis=1)
df
9) 데이터 프레임의 정보 보기
: info 사용하기
df.info()
10) 데이터 프레임의 크기 출력하기
: shape 사용하기
df.shape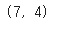
11) 데이터 타입만 보기
: dtypes 사용하기
df.dtypes
12) 데이터 프레임의 요약정보 가져오기
: describe 사용
-수치형 데이터의 기술통계값 보기
df.describe()
* count : 결측치를 제외한 빈도수
* mean : 평균
* std : 표준편차
* min : 최솟값
* '25%', '50%', '75%' : 값을 순차정렬 했을 때 앞에서부터 해당 위치에 있는 값.
* max : 최댓값
-범주형 데이터의 기술통계값 보기
df.describe(include='object')
* unique : 결측치를 제외한 빈도수
* top : 최빈값
* freq : 최빈값의 빈도수
13) 컬럼명으로 데이터 가져오기
df["영화제목"]
14) 두 개 이상의 컬럼명 한 번에 가져오기
: 대괄호를 두 겹으로 쓰기.
# 대괄호 하나만 썼을 때
df["영화제목", "평점"]
# 대괄호 두 개 썼을 때
df[["영화제목", "평점"]]
15) 인덱스 번호로 데이터 가져오기
: loc 사용하기
(loc : 인덱스, 컬럼명으로 데이터 가져오기 / iloc : 순서대로 값 가져오기)
df.loc[0]
# 행과 열을 동시에 지정하여 한 가지 데이터만 가져올 수 있음.
print(df.loc[0, "개봉일"])
df.loc[[1,2,5], ["영화제목", "개봉일"]]
16) 데이터 검색하기
: .str.contains 사용하기
df["영화제목"].str.contains("o|오")
** |는 or, &는 and의 의미를 갖는다.
**소문자와 대문자를 다른 글자로 인식한다.
=> 모두 소문자로 만든 후 검색하기
df["영화제목_소문자"] = df["영화제목"].str.lower()
17) 평점 8.5 이상의 영화만 출력하기
df[df["평점"] >= 8.5]
18) 정렬하기
: sort_values 사용하기
df.sort_values(by=["개봉일", "영화제목"], ascending=[True, True])
19) csv 파일로 저장하고 읽어오기
: to_csv, read_csv 사용하기
# csv 파일로 저장하기
df.to_csv("pandas_example.csv", index=False)# csv 파일 읽어오기
pd.read_csv("pandas_example.csv")
20) 엑셀 파일로 저장하고 읽어오기
: 확장자명 xlsx
# 엑셀로 파일 저장하기
df.to_excel("pandas_ex.xlsx", encoding='cp949', index=False)
**한글이 깨지기 때문에 인코딩 cp949를 해주어야 함.
* 오늘의 후기
☆ 사실(Fact) : 강사님과 함께 판다스 강의를 시작했다.
☆ 느낌(Feeling) : 어려워보였는데 강사님과 함께하니 해볼만 했다.
☆ 교훈(Finding) : 스스로 할 때에도 이렇게 공부해서 발전해야 하는구나를 알게 되었다.